Application de Suivi Qualité
Introduction
L’objectif de cet article est de partager l’expérience que nous avons acquise lors de l’adaptation de Request Tracker pour en faire un système de gestion de qualité industrielle.
Il s’adresse aux responsables et aux techniciens qui souhaitent mettre en place une solution de gestion d’incidents fondée sur le logiciel libre RT.
Introduction à la gestion d’incidents
La gestion d’incidents consiste à :
- alerter et déclarer ;
- valider et répondre ;
- suivre et chiffrer les incidents.
De nombreux professionnels ont besoin de ce type de fonctionnalités, notamment dans :
- les centres de support clients ;
- la gestion de parc informatique « Help desk » ;
- l’industrie.
Chaque profession dispose de son propre vocabulaire mais le processus de gestion est plus ou moins le même :
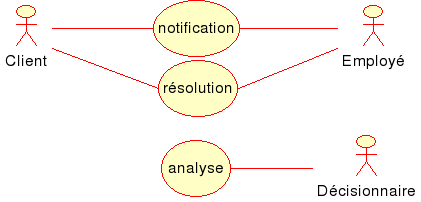
Solution libre « Request Tracker »
Request Tracker est un logiciel libre édité par la société « Best Pratical Solutions » sous licence GPL.
Il est composé de plusieurs éléments :
- un moteur de gestion de « tickets »
- une base de données relationnelle
- plusieurs interfaces : web, ligne de commande et messagerie.
Fonctionnalités
Les principales fonctionnalités du logiciel sont les suivantes :
- déclarer, assigner, organiser, rechercher et répondre à un incident ;
- la déclaration peut se faire via l’interface web ou bien via l’envoi d’un mail ;
- historique complet des actions et de toutes les modifications entreprises ;
- interface multi-utilisateurs et traduction en de nombreuses langues ;
- support de nombreux types de bases de données relationnelles (MySQL, Oracle, PostreSQL, etc.) ;
- décompte du temps passé ;
- moteur de recherche / extraction des informations.
La plus grande force du logiciel est la facilité de personnalisation :
- champs personnalisables (« Custom Fields »), il s’agit d’attribuer des champs de différents types à un événement ;
- scrips (scripts), il s’agit d’un système de macros déclenchées en fonction d’un événement. Par exemple, il est possible d’envoyer un mail à un responsable lorsqu’un certain type d’incident est signalé ;
- une multitude d’options de configuration ;
- une architecture modulaire.
RT est le logiciel libre de référence en matière de gestion d’incidents. Il est utilisé par de nombreuses entreprises ou organisations parmi lesquelles : la NASA, Merrill Lynch, Freshmeat, Free Telecom,... (voir la liste)
Analyse des besoins et des solutions proposées
Gestion Qualité Industrielle
Les missions du service Qualité du Client sont multiples :
- Alerter/informer d’une non-conformité ;
- Mettre en place des actions correctives afin de remédier à ces non-conformités ;
- Mettre en place des actions préventives ;
- Chiffrer les coûts des non-conformités et des actions de correction et prévention qu’elles engendrent.
Cette gestion nécessite de désigner des responsables d’action et de fixer des délais de réalisation. L’ensemble de ces éléments doivent être organisés et hiérarchisés pour mieux en assurer le traitement et le suivi.
Pertinence de l’utilisation d’un système de gestion d’incident
Partant du principe qu’une gestion de non-conformité et une gestion d’incidents répondent aux mêmes principes de traitement, l’adaptation de RT à une problématique Qualité devient alors une question de sémantique.
On ne parle plus d’incident, mais de non-conformité, on ne dit plus ticket, mais fiche qualité, un incident n’est plus résolu, mais une fiche est soldée, etc.
Néanmoins, il reste pertinent (et nécessaire) de se pencher sur les spécificités du Client en exploitant le fait que RT est très personnalisable.
En effet, l’objectif est, dans le mesure du possible, d’adapter l’outil aux pratiques du Client et non de le contraindre à une logique induite par un fonctionnement trop rigide du logiciel.
Personnalisation de la solution
Adaptation du processus
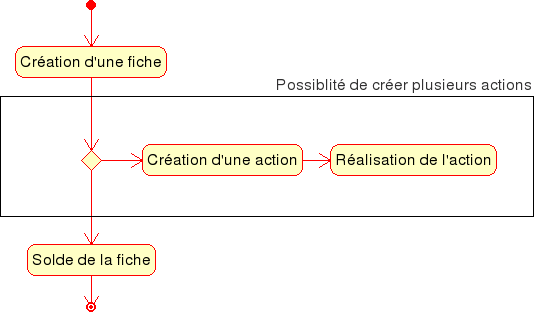
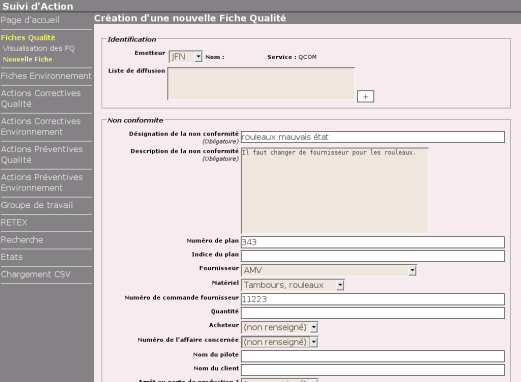
Pour chaque type d’incident, une fiche est créée. Celle-ci se présente sous forme d’un formulaire permettant d’identifier l’incident et d’informer les responsables par le biais d’une liste de diffusion :
Chaque fiche donne lieu à la mise en place de plusieurs actions avec pour chacune un responsable.
Une fois l’ensemble des actions qui composent une fiche réalisée, celle-ci est soldée.
Au cours de ce processus, les utilisateurs ont la possibilité :
- d’échanger des fichiers ;
- de communiquer par écrit.
Le service Qualité n’a plus qu’à valider l’ensemble des actions et à exploiter les informations fournies.
Exploitation des informations
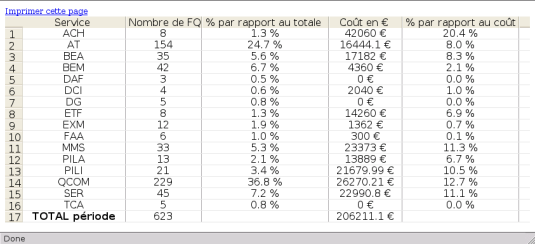
Pour exploiter l’ensemble des informations fournies, les utilisateurs disposent d’un moteur de recherche simplifié et d’un système d’extraction de statistiques : le moteur d’état.
Celui-ci permet principalement de calculer les coûts des incidents et de les afficher sous forme de tableaux :
Les problématiques techniques rencontrées et leurs solutions
Description de l’architecture du logiciel
Voici le schéma de l’architecture générale du logiciel. L’ensemble est écrit à l’aide du langage de programmation Perl.
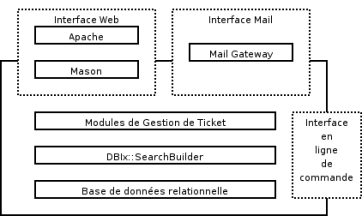
- Base de données relationnelle, le logiciel dispose d’une couche d’abstraction par rapport à la base de données grâce aux modules DBI ;
- Les requêtes effectuées sur la base sont construites par le biais du module DBIx::SearchBuilder ;
- Le coeur du logiciel est composé d’un ensemble de modules / classes Perl : Ticket, User, Group etc.
- Au dessus de ces modules sont greffées trois interfaces :
- en ligne de commande ;
- via la messagerie, il s’agit d’un script qui fonctionne comme le programme procmail ;
- web, celle-ci est écrite à l’aide du système de modèle Mason. Il s’agit d’un framework permettant la réalisation de site web en Perl. Cette interface fonctionne de plusieurs manières (CGI, FastCGI, mod_perl) à l’intérieur d’un serveur HTTP comme Apache.
Problématiques techniques et solutions de mise en oeuvre
Le piège des « Custom Fields »
Voici la structure utilisée pour prendre en charge les champs libres dans RT :
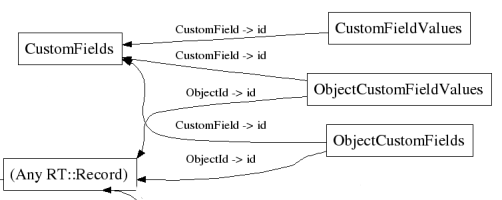
Cette structure est inspirée par les algorithmes de persistance objet, en effet les « custom fields » sont vus comme des attributs pour les objets (Ticket, Files, etc.).
Le principal problème de l’algorithme choisi est qu’il ne monte pas en charge, en effet il faut faire de nombreuses requêtes SQL pour obtenir la valeur d’un champ libre.
D’autres algorithmes, plus efficaces, mais plus complexes sont décrits dans le livre de référence.
Par conséquent, il ne faut pas abuser de cette fonctionnalité et limiter le nombre de champs personnalisés, dix nous semble être le maximum.
Si vous voulez étendre les attributs des différents objet, il est préférable de modifier le schéma de la base de données.
Complexité du moteur de recherche
Le moteur de recherche disponible par défaut dans le logiciel est extrêmement puissant. Il permet la création de requêtes « Ticket SQL », forme de SQL simplifiée permettant de rechercher dans la base de données. Ce moteur de recherche peut être est assez complexe pour un utilisateur.
Nous avons donc réécrit, un moteur de recherche simplifié. Avec un accès rapide aux recherches les plus fréquentes et un choix limité aux critères les plus importants.
Vision métier de la base de données
Le client avait besoin de voir et d’extraire les informations de la base de données. Dans un premier temps nous lui avons donné accès à la base de données du logiciel, mais cela est relativement complexe, notamment pour récupérer les valeurs contenues dans les champs personnalisés.
Pour contourner le problème nous avons mis en place un système de « View ». Celui-ci fonctionne de la manière suivante :
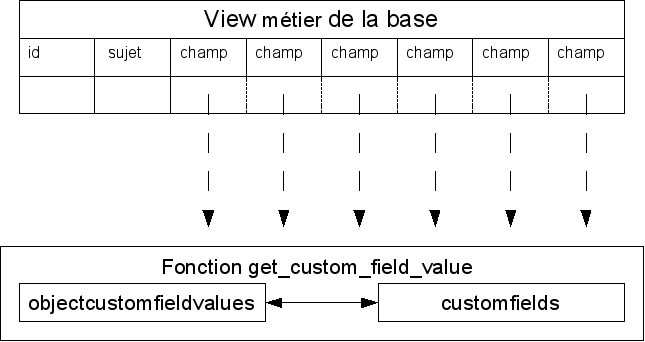
La base de données récupère les valeurs des champs personnalisés à l’aide d’une fonction PL/SQL, ce qui permet à l’utilisateur d’effectuer des interrogations sur les données. Les modifications sont prises en compte par une fonction.
Conclusion
Ce projet (et cet article) qui date de 2003 nous a permis de démontrer que RT pouvait répondre à de nombreux besoins en entreprise. Nous avons dû à l’époque développer de nombreuses fonctionnalités aujourd’hui présentes en standard dans l’outil, preuve de la vivacité du projet et de sa communauté d’utilisateurs, qui repoussent sans cesse les frontières des usages possibles.